

In today’s disruptive world of data science, where the fusion of technology, statistics, and domain expertise uncovers valuable insights and drives informed decision-making. As the demand for data scientists continues to surge, the interview process becomes a critical stepping stone towards landing your dream job in this dynamic field.
Whether you have just graduated or are experienced and are looking to switch careers or simply seeking to enhance your data science knowledge, mastering the interview process is essential. To help you navigate this competitive landscape, we present: “Top 100+ Data Science Interview Questions and Answers.” This comprehensive compilation is designed to equip you with the knowledge and confidence necessary to excel in the interviews for a data scientist role.

Why Data Science Interviews Matter
Data science interviews play a pivotal role in assessing your technical proficiency, problem-solving capabilities, and ability to apply data-driven methodologies to real-world challenges. Companies across various industries rely on interviews to evaluate candidates’ analytical thinking, programming skills, statistical knowledge, and domain expertise.
Given the complexity and multidisciplinary nature of data science, interviewers often probe candidates with a diverse range of questions. These questions may encompass theoretical concepts, statistical methods, machine learning algorithms, programming languages, data manipulation, and much more. To stand out from the competition, it is essential to possess a comprehensive understanding of these topics and their practical applications.
Exploring the Contents of this Blog: What to Expect
We have diligently curated this extensive collection of interview questions to provide you with a holistic view of the data science landscape. Data scientist questions can turn out to be quite intensive so it is good to have a guide to answering them. Each question has been meticulously crafted to challenge your knowledge and problem-solving abilities, enabling you to sharpen your skills and enhance your interview performance.
Data Science Interview Questions and Answers
What is meant by data science?
Data science is an interdisciplinary field that encompasses the extraction of valuable knowledge and insights from vast and complex datasets. By leveraging techniques like statistics, machine learning, and data visualisation, data scientists can identify patterns, trends, and correlations that help businesses make informed decisions and solve complex problems.
What are the key components of the data science process?
The key components of the data science process are data collection, data cleaning and preprocessing, exploratory data analysis, modelling, evaluation, and deployment, with each step contributing to the overall goal of deriving meaningful insights and actionable outcomes from data.
Differentiate between supervised and unsupervised learning.
In supervised learning, labelled data is what is used.While unsupervised learning deals with unlabeled data and aims to find patterns or structures in the data.
What is over-fitting?
It is a phenomenon that occurs when a model works well during the training data but fails to generalize to unseen data, highlighting the model’s inability to adapt and perform accurately in real-world scenarios. This issue, known as overfitting, can lead to misleading results and hinder the model’s practical usefulness.
Table of Contents
How can overfitting be prevented?
It can be prevented by techniques such as cross-validation, regularization, and using more data, which help in constraining the model’s complexity, improving its ability to generalise, and reducing the risk of overfitting. These approaches enhance the model’s performance and reliability across various data samples.
Explain the bias-variance tradeoff.
The bias-variance tradeoff refers to the inherent tradeoff between the bias of a model (underfitting) and its variance (overfitting), wherein reducing one component often results in an increase in the other, making it essential to strike the right balance for optimal model performance.
What is the curse of dimensionality?
Dimensionality refers to the problems that arise when one works with high-dimensional data, where the vast number of features or variables can lead to increased computational complexity, decreased model interpretability, and a heightened risk of overfitting, making it challenging to extract meaningful patterns and insights from the data.
What is the Central Limit Theorem?
Central Limit Theorem states that the sum or an average of a large number of independent, random variables will follow a sort of normal distribution, regardless of the shape of the original distribution, making it a fundamental principle in statistics and enabling various statistical techniques to be applied with confidence in real-world scenarios.
What is the difference between Type I and Type II errors?
Type I error, also known as a false positive, occurs when a true null hypothesis is incorrectly rejected, leading to the acceptance of an effect or relationship that doesn’t exist, while Type II error, or a false negative, happens when a false null hypothesis is not rejected, resulting in the failure to identify a significant effect or relationship that actually exists in the population.
Explain the concept of the term “ensemble learning” in machine learning.
Ensemble learning involves combining multiple models, often of diverse types or trained on different subsets of data, to make predictions or decisions, harnessing the collective wisdom and strengths of individual models to improve overall performance and enhance the accuracy and robustness of the final predictions.
What is the difference between bagging and boosting?
Bagging (Bootstrap Aggregating) combines multiple models trained on different subsets of the data while boosting combines weak models sequentially, with each model learning from the mistakes of the previous ones.
Why should there be regularisation in machine learning?
Regularization prevents overfitting by adding a penalty term to the loss function, encouraging the model to learn simpler patterns and avoid excessive complexity, thereby striking a balance between fitting the training data well while still generalizing effectively to unseen data, leading to a more reliable and practical model.
What are the assumptions of linear regression?
Linear regression relies on four key assumptions: linearity between independent and dependent variables, independence of errors, constant variance of errors (homoscedasticity), and normality of errors, forming the bedrock for dependable and precise linear regression analysis.
Explain the difference between correlation and causation.
Correlation measures the statistical relationship between two variables, quantifying the degree of association or dependency between them, whereas causation goes beyond correlation by indicating a direct cause-and-effect relationship, suggesting that changes in one variable lead to a corresponding change in the other, providing deeper insights into the underlying mechanisms governing the data.
What is feature selection?
Feature selection is the process of selecting the most relevant and informative features from a dataset, while discarding irrelevant or redundant ones, aiming to improve model performance, reduce computational complexity, and enhance interpretability by focusing on the most influential attributes that contribute significantly to the target variable prediction.
What is the purpose of cross-validation?
Cross-validation is used to estimate the performance of a model on unseen data by partitioning the available data into multiple subsets (folds) for training and validation, allowing for a more robust evaluation of the model’s generalization ability and reducing the risk of overfitting, making it a valuable technique in model selection and hyperparameter tuning.
How would you handle missing data in a dataset?
Missing data can be handled by removing the rows or columns with missing values, imputing the missing values with statistical measures (e.g., mean, median), or using advanced imputation techniques such as regression or multiple imputation.
Explain the difference between precision and recall.
Precision measures the accuracy of positive predictions, while recall highlights the model’s ability to capture relevant instances; achieving a balance between these metrics is crucial in applications like medical diagnoses or spam detection, where false positives and false negatives can have significant consequences.
What is the purpose of dimensionality reduction?
Dimensionality reduction techniques, like PCA and t-SNE, help visualize data in lower-dimensional spaces, improve model performance by mitigating overfitting and multicollinearity risks, and reduce computational complexity by minimizing features, making it crucial for handling high-dimensional datasets and extracting meaningful insights.
What is the purpose of a confusion matrix?
The confusion matrix is a powerful tool used to evaluate the performance of a classification model by displaying counts of true positive, true negative, false positive, and false negative predictions, enabling a comprehensive assessment of the model’s accuracy and error rates.
What is the purpose of gradient descent in machine learning?
It is an optimization algorithm used to minimize the loss function of a model by iteratively adjusting the model’s parameter in the direction of the steepest descent.
How does k-means clustering work?
The k-means clustering is an unsupervised learning algorithm that partitions data into k clusters, where each cluster is represented by its centroid, minimising the intra-cluster distance and maximising the inter-cluster distance, making it widely used for data segmentation and pattern recognition tasks.
Explain the concept of TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) is a numerical representation used to measure the importance of a term in a collection of documents by considering its frequency in a document and its rarity across the entire corpus.
What is the purpose of a ROC curve?
A Receiver Operating Characteristic (ROC) curve is helpful in evaluating the performance of a binary classification model by plotting the true positive rate against the false positive rate at various classification thresholds.
How do you handle multicollinearity in regression models?
Multicollinearity, which occurs when predictor variables are highly correlated, can be handled by removing one of the correlated variables, combining them into a single variable, or using dimensionality reduction techniques such as principal component analysis (PCA).
Explain the concept of cross-entropy loss.
Cross-entropy loss is a commonly used loss function in classification tasks. It measures the dissimilarity between the predicted probabilities and the true labels, providing a measure of how well the model is performing.
What is the purpose of the cosine similarity measure?
It is a measure of how similar two vectors are. It is often used in text mining and recommendation systems to compare the similarity of documents or items.
Explain the concept of transfer learning in deep learning.
Transfer learning involves using pre-trained models as a starting point for a new task or dataset. By leveraging the knowledge learned from a large and diverse dataset, transfer learning allows for faster and more accurate model training on a smaller dataset.
Explain the concept of cross-validation and its advantages
Cross-validation is a resampling technique that involves partitioning the data into multiple subsets, training and evaluating the model on different combinations of these subsets. It also helps in assessing model generalisation.
How do you handle skewed data distributions?
Skewed data distributions can be handled by applying transformations such as logarithmic or power transformations to normalise the data or using algorithms that are less sensitive to skewness, such as decision trees or random forests.
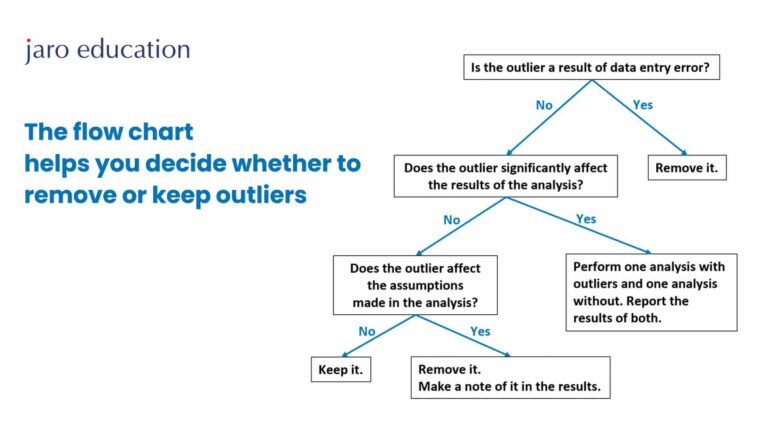
How do you handle outliers in a dataset?
Outliers can be handled by either removing them if they are caused by errors, applying transformations to make the distribution more symmetric, or using robust statistical techniques that are less influenced by extreme values.
Explain the purpose of the chi-square test of independence.
It is used to determine whether there is a relationship between two categorical variables. It assesses whether the observed frequency distribution differs significantly from the expected frequency distribution under the assumption of independence.
What is the purpose of the AdaBoost algorithm?
AdaBoost is an ensemble learning algorithm. It assigns higher weights to misclassified samples in each iteration, allowing subsequent weak models to focus on the difficult samples.
Explain the concept of a dendrogram in hierarchical clustering.
A dendrogram is a tree-like structure that represents the hierarchical clustering of data. It illustrates the arrangement of clusters and their similarities based on the distance between data points.
How do you handle the problem of multi-label classification?
Multi-label classification problems involve predicting multiple labels for a single instance. They can be addressed using techniques such as binary relevance, classifier chains, or label powerset.
Explain the concept of deep learning and its applications
Deep learning is a subset of machine learning that utilises artificial neural networks with multiple layers to learn hierarchical representations from data, enabling it to excel in complex tasks such as image recognition, speech recognition, natural language processing, and autonomous driving, driving remarkable advancements in artificial intelligence across diverse industries.
How would you handle a situation where your model is suffering from high bias?
High bias can be addressed by increasing model complexity, adding more features, or using more advanced algorithms that can capture complex relationships in the data.
How do you handle imbalanced classes in a classification problem?
Imbalanced classes can be handled by techniques such as oversampling the minority class, undersampling the majority class, or using algorithms that are specifically designed to handle imbalanced data, such as cost-sensitive learning or ensemble methods.
Explain the concept of the F1 score and its significance.
It is a metric that combines precision and recall into a single value. It provides a balanced measure of model performance, particularly in situations where there is class imbalance.
What is the purpose of the term “XGBoost” in machine learning?
XGBoost is an optimised gradient-boosting algorithm that is known for its speed and performance. It provides better regularisation, handling of missing values, and parallel processing compared to traditional gradient boosting.
How do you handle the problem of high-dimensional data in machine learning?
High-dimensional data can be handled by applying dimensionality reduction techniques such as PCA (Principal Component Analysis), LDA (Linear Discriminant Analysis), or feature selection methods to identify the most informative features.
Explain the concept of the PageRank algorithm in web page ranking.
The PageRank algorithm is an algorithm used to rank web pages based on their importance. It assigns a score to each web page. The ones with higher scores indicate higher importance.
What is the purpose of the term “regularisation path” in linear regression?
The regularisation path in linear regression represents the sequence of models obtained by varying the regularisation parameter, allowing us to observe how the regularisation affects the model’s coefficients and how it can influence feature selection, providing insights into the trade-off between model complexity and performance.
How would you handle a class imbalance in a multi-class classification problem?
Class imbalance in multi-class classification can be handled by techniques such as oversampling the minority classes, undersampling the majority class, or using algorithms that can handle imbalanced data, such as cost-sensitive learning or one-vs-rest classification.
Explain the concept of the Gini index in decision trees.
It is a measure of impurity used in decision tree algorithms to evaluate the quality of a split. It measures the probability of misclassifying a randomly chosen element if it was randomly labelled according to the distribution of classes in the node.
Explain the concept of the Gaussian Naive Bayes algorithm.
Gaussian Naive Bayes is a probabilistic classification algorithm that assumes that the features follow a Gaussian distribution. It applies Bayes’ theorem to calculate the posterior probability of each class given the input features.
What is the purpose of the term “K- Nearest Neighbors (KNN)” in machine learning?
The purpose of the term “K-Nearest Neighbors (KNN)” in machine learning is to classify or predict an instance by considering the labels of its nearest neighbours in the training data. It is a simple yet effective classification and regression technique that relies on local patterns in the data.
How would you handle the problem of outliers in a dataset?
Outliers can be handled by either removing them if they are caused by errors or measurement issues, applying transformations to make the distribution more symmetric, or using robust statistical techniques that are less influenced by extreme values.
Explain the concept of the Markov chain Monte Carlo (MCMC) method.
Markov chain Monte Carlo (MCMC) is a class of algorithms used to generate samples from complex probability distributions. It uses Markov chain principles to sample from a distribution by iteratively updating the current state based on transition probabilities.
What is the purpose of the term “support vector machines (SVM)” in machine learning?
Support Vector Machines (SVM) is a powerful supervised learning algorithm used for classification and regression. It finds the optimal hyperplane that separates the data into different classes or predicts the continuous target variable.
It’s important to note that the actual interview questions may vary depending on the specific company, job role, and interviewer preferences. Therefore, it’s recommended to supplement your preparation with additional research and practice.
In addition to knowing the technical aspects, also focus on your problem-solving skills, ability to communicate effectively, and demonstrate your passion for data science. Practice coding and working with real-world datasets, and don’t forget to brush up on your statistical knowledge.
Lastly, be confident and enthusiastic, and showcase your willingness to learn and grow in the field of data science. Good luck with your interviews, and we hope this blog has provided you with a valuable resource to ace your data science interviews!
Trending Blogs







