How to Get Datasets for Machine Learning?
Table of Contents

- jaro education
- 11, March 2024
- 2:00 pm
The availability and quality of datasets for machine learning play a pivotal role in model development and training. The process of acquiring suitable datasets is a critical initial step for data scientists. This involves sourcing diverse and relevant data to ensure the effectiveness of machine learning models. Here, we will explore various methods and considerations involved in obtaining datasets for machine learning applications.
What is a Dataset?
A dataset comprises data organized into a collection that developers can utilize to achieve their objectives. In a dataset, rows correspond to individual data points, while columns represent the features of the dataset. These are commonly employed in domains such as machine learning, business, and government to garner insights, make informed decisions, or train algorithms. Datasets come in diverse sizes and complexities, often necessitating cleaning and preprocessing to guarantee data quality and suitability for analysis or modeling.
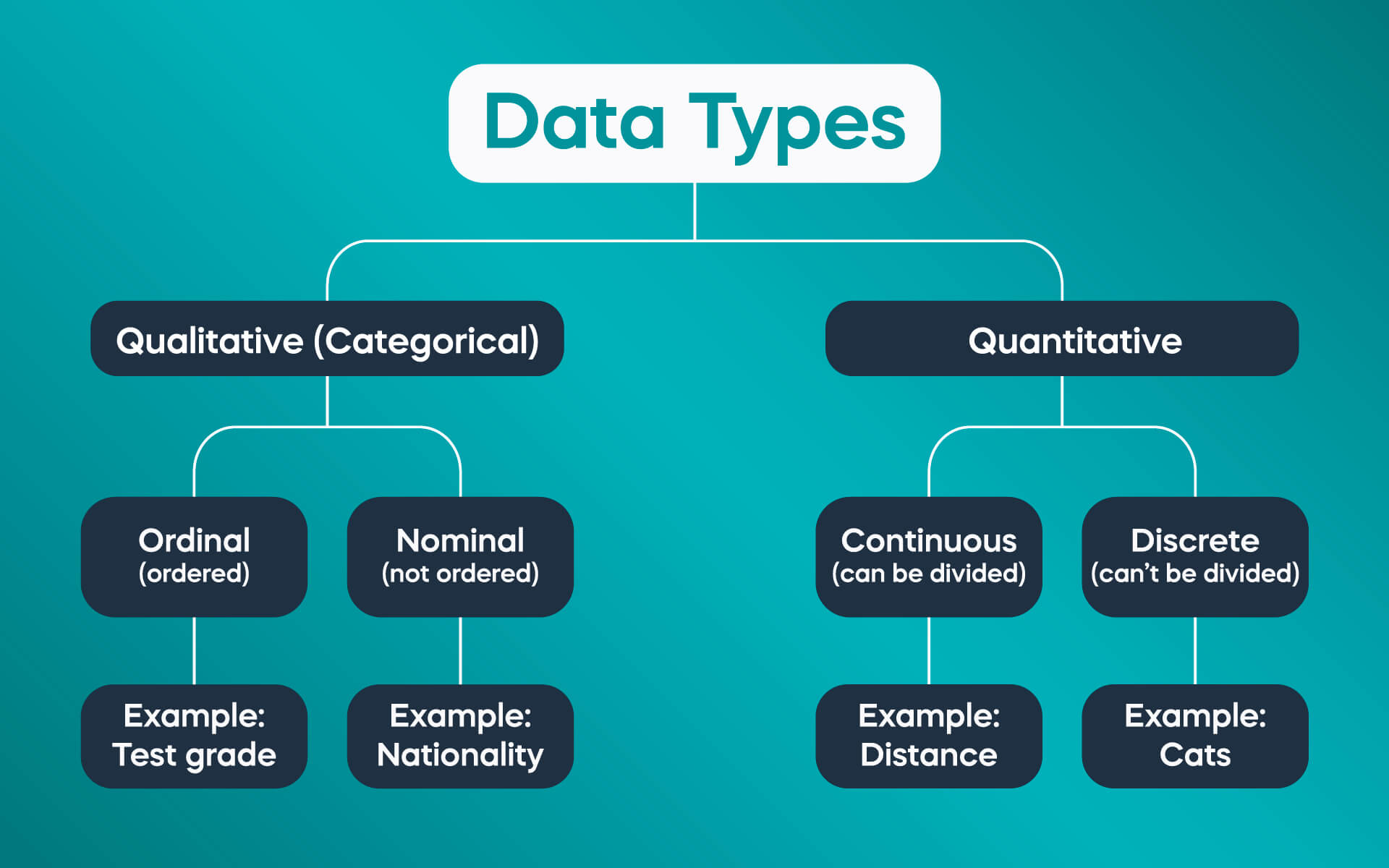
Types of Data in Dataset
Within datasets for machine learning projects, various data types serve distinct purposes:
- Integer (int): It is a numeric data type for whole numbers without fractions.
- Floating Point (float): It is a numeric data type for numbers with fractions.
- Character (char): Represents a single letter, digit, punctuation mark, symbol, or blank space.
- String (str or text): A sequence of characters, digits, or symbols always treated as text.
- Boolean (bool): Represents true or false values.
- Enumerated type (enum): Consists of a small set of predefined unique values, which can be text-based or numerical.
- Array: A list with a specific order, typically containing elements of the same type.
- Date: Represents a date in the YYYY-MM-DD format (ISO 8601 syntax).
Types of Dataset
Various types of datasets for ML projects exist, each categorized based on the information it contains. The main types include:
- Numerical Dataset: It comprises numerical values suitable for mathematical calculations.
- Categorical Dataset: It focuses on the characteristics of a person or object.
- Bivariate Dataset: The dataset consists of two variables, analyzed for their relationship.
- Multivariate Dataset: Involves more than two variables, each representing unique values.
- Correlation Dataset: This dataset indicates a relationship between variables.
*365datascience.com
Need for Dataset in Machine Learning
Machine learning datasets serve as structured and organized repositories of data, empowering sophisticated algorithms to discern patterns, make predictions, and derive meaningful insights. As an example, a medical dataset contains information like medical records or insurance records, and it serves as a resource for programs running on the system.
Data Licensing and Usage Rights
Data licensing involves the provision of licenses for the use of data, considering various factors related to ownership, generation, and confidentiality. Key considerations include:
Ownership and Use of Data
In most cases, the third-party use of data requires a license from the data owner or a sublicense from an authorized party.
Competing Interests in Data Processing
In data processing, conflicting interests arise when a service vendor aims for analysis, aggregation, and potential licensing, while customers prioritize privacy. The challenge lies in finding a balance, ensuring transparent communication, robust data protection, and ethical use. Striking this equilibrium is crucial for fostering trust and responsible data management.
Customer Concerns and Objectives
- Customers typically aim to maintain data confidentiality and restrict its use for their benefit.
- Access to and ownership of any new data sets resulting from the vendor’s processing are key considerations.
Data Delivery, Maintenance, and Security
- Licensing agreements should address the manner of data delivery, maintenance, and control, particularly for personal or sensitive information.
- Protocols and practices for data security need to be clearly defined.
Data Use Considerations
- Both data licensors and licensees must carefully assess legal and business considerations related to data use.
- Licensors often limit data use by specifying permitted uses, maintaining confidentiality, and outlining security measures.
Vendor-Licensee Relationship
- In a service relationship, licensors may restrict the vendor’s use of customer data to fulfill contractual obligations.
- Agreement terms should specify the scope of permissible uses and the licensee’s commitment not to exploit the data beyond agreed-upon parameters.
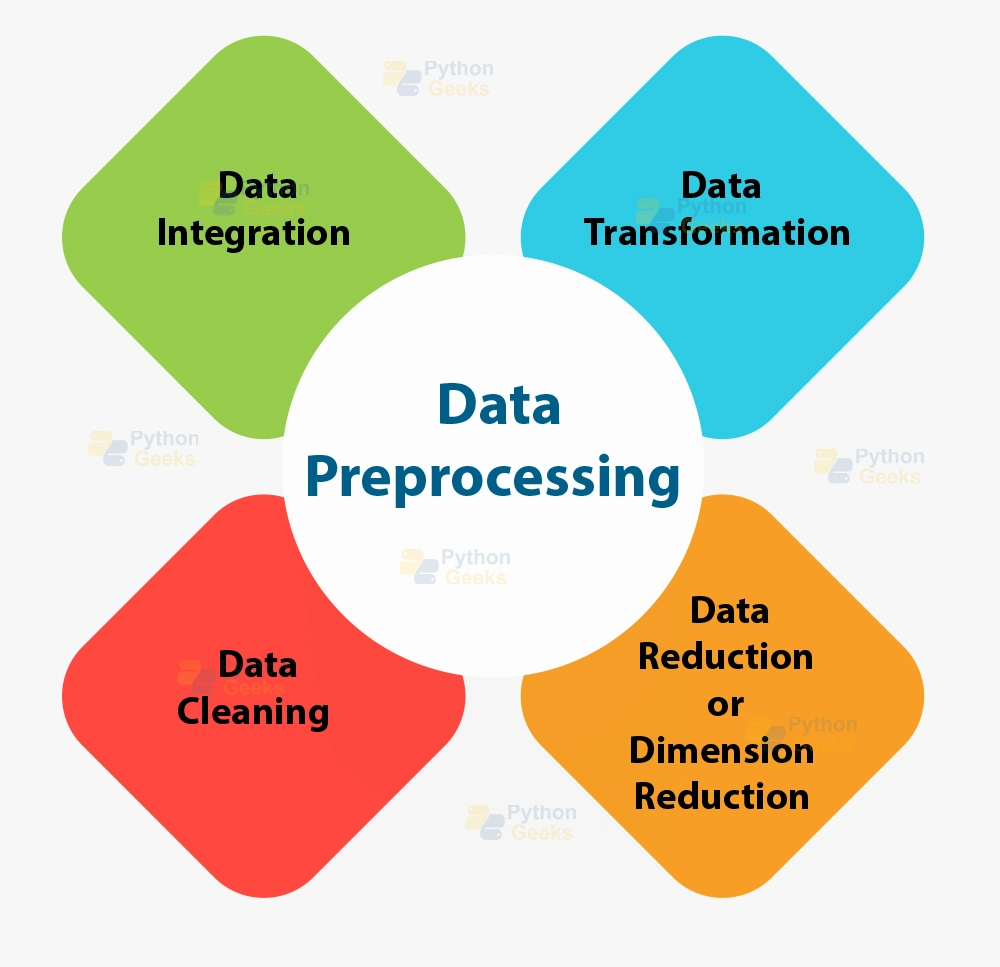
Data Cleaning and Preprocessing
Data Cleaning
In the field of data science and machine learning, ensuring the quality of input data is crucial. Data cleaning involves detecting and correcting or removing inaccurate records from a dataset. It goes beyond simply erasing data, encompassing techniques like handling missing values, removing duplicates, and converting data types. This process transforms raw data into a format suitable for analysis, contributing significantly to the performance of machine learning models.
Data Preprocessing
It is a vital step in data science, specifically for machine learning applications. It focuses on preparing and cleaning datasets to enhance their suitability for machine learning algorithms. Through Exploratory Data Analysis, issues such as inconsistencies, typos, and missing data are identified and addressed. This step is essential for improving model performance by reducing complexity, preventing overfitting, and ensuring the dataset’s completeness and accuracy. Techniques include dimensionality reduction, feature engineering, data sampling, transformation, and handling imbalanced data. Neglecting data preprocessing can impact model performance and downstream tasks.
*pythongeeks.org
Data Augmentation
Data augmentation is a method that involves artificially expanding the training set by producing modified replicas of a dataset using the existing data. This process entails introducing slight alterations to the dataset or employing deep learning methods to generate novel data points.
Data Bias and Fairness
Machine learning inherently faces the challenge of learning from data, making it susceptible to absorbing human biases present in the training data. Bias in machine learning leads to systematically distorted predictions, creating models that exhibit errors or losses when evaluated on test sets. Recognizing and addressing biases is essential to ensure fairness in decision-making processes and avoid discriminatory outcomes. Fairness in machine learning is essentially about achieving equal outcomes for individuals unless a meaningful distinction justifies differentiation.
Data Storage and Management
Management of data storage involves the oversight and optimization of the pivotal element within big data that gathers and preserves digital information through computers and other devices. This process is centered on efficiently handling data, necessitating a sound comprehension of storage devices and the accessibility of diverse data types.
Digital information encompasses protocols, documents, user preferences, address books, and various other forms. Various types of data storage, including object storage, file storage, software-defined storage, and block storage, cater to distinct purposes. The effective management of data storage ensures the organized handling of these diverse data types.
Conclusion
In machine learning, acquiring diverse and high-quality datasets is crucial. Understanding data types, licensing considerations, and addressing biases are essential. Effective data cleaning, preprocessing, and storage management are vital for robust model development. Prioritizing fairness ensures ethical and unbiased machine learning outcomes, emphasizing the need for diligence in every stage of the data journey.
To build a career in the machine learning field, the Executive Programme in Applied Data Science using Machine Learning & Artificial Intelligence, offered by CEP, IIT Delhi, can be your righteous resort. It is designed as per the growing need for machine learning and provides executives and professionals with essential skills to excel in the field. This course facilitates business growth and encourages innovation, enabling professionals to master datasets and apply the potential of tools and languages like Python, Pandas, NumPy, etc., in their specific industries.
Frequently Asked Questions
Why is artificial intelligence in cybersecurity important?
Cybercriminals are continuously improving their attacking abilities with the help of AI. Now they are launching large-scale attacks by integrating AI technologies into their workflows. To prevent these attacks, you should utilise AI to analyse large volumes of data, reducing false positives from security alerts and cutting out bottlenecks from security alerts.
What are the major benefits of AI cybersecurity?
The major benefits of AI-based cybersecurity include –
- Quickly analysing large volumes of data
- Automating the repetitive cybersecurity tasks
- Predicting potential attacks and providing messages to the security teams
Mention some important skills required for a professional in AI cybersecurity.
To become a professional in AI cybersecurity, you need knowledge about ML data modelling, language modelling, behaviour analysis, and deep neural networks. For cybersecurity, you need a clear understanding of network security, cryptography, malware detection, data protection, and computer forensics.
Can AI replace human input in cybersecurity?
No, AI can perform specific tasks in cybersecurity, but it can’t completely replace human input.
Can we automate cybersecurity workflows?
Yes, the cybersecurity professionals can automate the mundane tasks with the help of AI.
| Basis | Perfect Competition | Monopoly |
|---|---|---|
| Number of Sellers | firms | Single firm |
| Barriers to Entry | Very low | Very high |
| Substitute Products | Good substitutes are readily available | No good substitutes are available |
| Competitive Strategy | Firms compete through prices only | Companies compete through product features, quality, advertising, and marketing |
| Pricing Power | Negligible, dependent on supply and demand | Significant, companies can manipulate prices as desired |
"I had a wonderful journey taking this course by Prof. Chitra Singla on Strategic Management. It helped me gain a lot of insights and clarity. I am better able to engage with my clients for their strategic business needs now with this newfound clarity. Jaro did a wonderful job in organizing and communicating promptly in a helpful manner. The timing and schedules were quite convenient with my work as well."
Arun VelayudhanAssistant Professor, Farook Institute of Management Studies
Programme on Strategic Management
Programme on Strategic Management
"I had a wonderful journey taking this course by Prof. Chitra Singla on Strategic Management. It helped me gain a lot of insights and clarity. I am better able to engage with my clients for their strategic business needs now with this newfound clarity. Jaro did a wonderful job in organizing and communicating promptly in a helpful manner. The timing and schedules were quite convenient with my work as well."
Arun VelayudhanAssistant Professor, Farook Institute of Management Studies
Programme on Strategic Management
Programme on Strategic Management
"I had a wonderful journey taking this course by Prof. Chitra Singla on Strategic Management. It helped me gain a lot of insights and clarity. I am better able to engage with my clients for their strategic business needs now with this newfound clarity. Jaro did a wonderful job in organizing and communicating promptly in a helpful manner. The timing and schedules were quite convenient with my work as well."
Arun VelayudhanAssistant Professor, Farook Institute of Management Studies
Programme on Strategic Management
Programme on Strategic Management
"I had a wonderful journey taking this course by Prof. Chitra Singla on Strategic Management. It helped me gain a lot of insights and clarity. I am better able to engage with my clients for their strategic business needs now with this newfound clarity. Jaro did a wonderful job in organizing and communicating promptly in a helpful manner. The timing and schedules were quite convenient with my work as well."
Arun VelayudhanAssistant Professor, Farook Institute of Management Studies
Programme on Strategic Management
Programme on Strategic Management
"I had a wonderful journey taking this course by Prof. Chitra Singla on Strategic Management. It helped me gain a lot of insights and clarity. I am better able to engage with my clients for their strategic business needs now with this newfound clarity. Jaro did a wonderful job in organizing and communicating promptly in a helpful manner. The timing and schedules were quite convenient with my work as well."
Arun VelayudhanAssistant Professor, Farook Institute of Management Studies
Programme on Strategic Management
Programme on Strategic Management
"I had a wonderful journey taking this course by Prof. Chitra Singla on Strategic Management. It helped me gain a lot of insights and clarity. I am better able to engage with my clients for their strategic business needs now with this newfound clarity. Jaro did a wonderful job in organizing and communicating promptly in a helpful manner. The timing and schedules were quite convenient with my work as well."
Arun VelayudhanAssistant Professor, Farook Institute of Management Studies
Programme on Strategic Management
Programme on Strategic Management
"I had a wonderful journey taking this course by Prof. Chitra Singla on Strategic Management. It helped me gain a lot of insights and clarity. I am better able to engage with my clients for their strategic business needs now with this newfound clarity. Jaro did a wonderful job in organizing and communicating promptly in a helpful manner. The timing and schedules were quite convenient with my work as well."
Arun VelayudhanAssistant Professor, Farook Institute of Management Studies
Programme on Strategic Management
Programme on Strategic Management



Trending Blogs




1 thought on “How to Get Datasets for Machine Learning?”
Thank you for the valuable information on the blog.I am not an expert in blog writing, but I am reading your content slightly, increasing my confidence in how to give the information properly. Your presentation was also good, and I understood the information easily.
For more information Please visit the 1stepGrow website or AI and data science course.