Data Preprocessing in Data Mining: A Hands-On Guide
J
By Shubham Lal
May 1, 202611 min read
Published on May 1, 2026
SHARE THIS ARTICLE
Table Of Content
What is Data Preprocessing? From Raw Noise to Refined Signal
The Critical Role of Data Preprocessing in Machine Learning
5 Major Steps of Data Preprocessing Techniques
Data Cleaning: Handling the Mess
Ask any working data scientist where most of their time actually goes, and the answer is rarely "building models." It's cleaning, transforming, and organizing data. Studies consistently show that data preprocessing consumes roughly 80% of a project's total timeline — leaving just 20% for the modeling and analysis that gets all the glory.
This imbalance reveals a fundamental truth about data science: the quality of your output is entirely determined by the quality of your input. This is the essence of the "Garbage In, Garbage Out" (GIGO) principle — feed a sophisticated AI model corrupted, incomplete, or inconsistent data, and it will produce confidently wrong predictions at scale. In modern machine learning, that's not just an academic concern; it's a business risk.
The difference between a hobbyist and a professional data scientist is not the algorithm they choose – it's the rigor they apply before the algorithm ever runs.
Organizations making high-stakes, data-driven decisionsin finance, healthcare, and retail cannot afford to skip this foundation. Skipping it means flawed insights and costly errors downstream.
So what exactly happens during preprocessing — and why is real-world data so messy to begin with?
What is Data Preprocessing? From Raw Noise to Refined Signal
Think of raw data like crude oil. It’s valuable in theory, but completely unusable until it goes through a refinery. Data preprocessing is that refinery — the systematic process of transforming messy, inconsistent raw data into a clean, structured format that analytical tools and algorithms can actually work with.
At its core, data preprocessing is the set of techniques applied before any modeling or analysis begins. According to Data Preprocessing in Data Mining, this stage encompasses everything from correcting errors to restructuring datasets into consistent schemas.
Real-world data is inherently “dirty”. Common problems include:
Missing values — fields left blank due to sensor failures, user skips, or system errors
Noise — random errors or outliers that distort true patterns
Inconsistencies — the same city entered as “NYC,” “New York,” and “new york city” across records
Duplicate entries — the same record captured multiple times
These aren’t edge cases. They’re the norm in any production dataset.
Clean data is not the starting point — it’s the destination, and preprocessing is the journey every dataset must take before it delivers real insight.
Data cleaning sits at the foundation of the broader data science lifecycle, upstream of every model, dashboard, and business decision that follows. It’s worth noting that data preprocessing in machine learning extends this foundation further — shaping not just data quality, but model behavior itself. That connection between clean data and algorithm performance is exactly where things get even more critical.
The Critical Role of Data Preprocessing in Machine Learning
Understanding what is data preprocessing becomes especially clear when you look at how machine learning algorithms actually work under the hood. At their core, most algorithms operate on numbers — matrices of numerical values that represent patterns in data. Raw text strings, categorical labels like “red” or “blue,” and inconsistent date formats are essentially invisible to these models. Before any learning can happen, that raw input must be converted into a structured numerical form the algorithm can actually process.
The stakes go beyond simple compatibility. When preprocessing is skipped or done carelessly, models don’t just perform poorly — they learn the wrong lessons entirely. Imbalanced class distributions, for example, can cause a classifier to favor the majority class, producing results that look accurate on paper but fail completely in real-world deployment. As noted in A Brief Introduction to Data Preprocessing, poor data quality is one of the most consistent contributors to model degradation across predictive tasks.
Feature scaling is another area where preprocessing has a measurable, direct impact. Distance-based algorithms like K-Nearest Neighbors (KNN) and Support Vector Machines (SVM) calculate relationships between data points using numerical proximity. If one feature ranges from 1 to 10 and another ranges from 1,000 to 100,000, the larger-scale feature will dominate every calculation — not because it’s more important, but simply because it’s bigger. Unscaled features silently distort model behavior in ways that are genuinely difficult to diagnose after the fact.
Business intelligence tools face the same dependency. Dashboards and reporting systems built on dirty or inconsistent data generate misleading insights, no matter how well-designed the visualization layer is. Clean data isn’t just a modeling concern — it’s the foundation of trustworthy analytics at every level.
With the importance of preprocessing firmly established, it’s worth examining exactly how it gets done — and that means breaking the process down into its core stages.
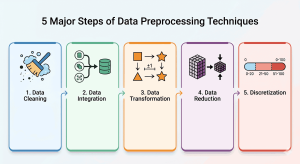
Now that you understand why preprocessing matters, it’s time to look at how it actually works in practice. The core data preprocessing techniques used across data mining projects can be organized into five foundational steps: Cleaning, Integration, Transformation, Reduction, and Discretization. Together, these steps form a working framework that takes raw, unreliable data and converts it into something a model can genuinely learn from.
The most important thing to understand upfront: these steps are iterative, not a strict assembly line. In practice, you might clean data, attempt integration, discover new inconsistencies, and loop back to cleaning again. Real-world data pipelines rarely move in a straight line.
Step 1: Data Cleaning
Cleaning addresses the foundational problems — missing values, duplicate records, and outliers that could distort your results. This is often the most time-consuming phase. As noted in Data Preprocessing in Data Mining, the quality of the final model is tightly coupled to the rigor applied during this stage. (More on the specific techniques for cleaning — including imputation methods and outlier detection — in the very next section.)
Step 2: Data Integration
Once individual datasets are cleaned, they often need to be merged. Data integration combines data from multiple sources — databases, APIs, flat files — into a single, coherent dataset. The challenge here isn’t just technical; it requires careful handling of naming conflicts, redundant attributes, and schema mismatches. Tools like SQL, Apache Spark, and Python’s pandas library are staples for this work.
Step 3: Data Transformation
Raw data rarely arrives in the shape an algorithm expects. Transformation reshapes values to make them compatible and comparable — think normalizing numeric ranges, encoding categorical variables, or applying log transformations to skewed distributions. This step directly impacts model convergence speed and prediction accuracy. Professionals working inmachine learning engineering or feature engineering spend a significant portion of their time here.
Step 4: Data Reduction
More data isn’t always better. Data reduction trims the dataset down to its most informative features without losing predictive power. Techniques like Principal Component Analysis (PCA), feature selection, and sampling fall under this umbrella. Reducing dimensionality also lowers computational costs — a critical concern when working with large-scale datasets in production environments.
Step 5: Discretization
Some algorithms – particularly decision trees and Naive Bayes classifiers – perform better with categorical inputs rather than continuous numerical values. Discretization converts continuous variables into discrete bins or intervals. For example, an age variable might be bucketed into ranges like 18–25, 26–35, and so on. It’s a nuanced step that requires domain knowledge to execute without losing meaningful signal.
Every serious data practitioner needs fluency across all five of these stages — not just one or two. Whether you’re pursuing a role in data science, analytics engineering, or machine learning, this framework maps directly to the tools and skills employers value most.
Of course, knowing the framework is only half the battle. The real complexity lives inside each individual step. Up next: a deep dive into data cleaning, where the messiest — and most revealing — work actually happens.
Data Cleaning: Handling the Mess
With the why and the what of preprocessing firmly established, it’s time to roll up your sleeves. Data cleaning is where abstract principles meet practical execution — and where most of the real work happens.
Missing values are the first obstacle. Three standard imputation strategies cover most situations:
Mean imputation — best for normally distributed numerical data
Median imputation — preferred when outliers skew the distribution
Mode imputation — the go-to for categorical variables
Outlier detection comes next. Z-score flags values beyond ±3 standard deviations, while the IQR method caps extremes using the interquartile range. Both approaches prevent a single anomalous data point from distorting an entire model.
Clean data isn’t just accurate data — it’s data that a model can actually learn from without being led astray.
Finally, deduplication eliminates redundant records that inflate patterns artificially. Exact-match and fuzzy-match strategies both have a role here, depending on how consistently source data was entered.
These three pillars of data cleaning set the stage for the next challenge: combining and reshaping data from multiple sources through integration and transformation.
With your data cleaned, the next challenge is making it speak a consistent language. Data integration and transformation convert raw, mismatched inputs into a unified, model-ready dataset.
Schema matching and entity resolution are the first hurdles when merging multiple databases. Two systems might store the same customer as “CustID” and “customernumber” — resolving these conflicts requires careful field mapping before any analysis begins.
Transformation then standardizes how values are scaled. Two common approaches:
Min-Max normalization rescales values to a fixed range (typically 0–1), preserving original distributions
Z-score standardization centers data around a mean of 0, which works better when outliers are present
Encoding categorical variables is equally critical. Algorithms process numbers, not labels – so text categories like “red,” “blue,” or “green” must be converted using techniques like one-hot encoding or label encoding.
Properly transformed data doesn’t just feed the algorithm — it determines whether the algorithm learns anything meaningful at all.
In practice, skipping transformation steps is one of the most common reasons models underperform on otherwise clean datasets. Once your data is integrated and scaled correctly, the next logical question becomes: do you even need all of it? That’s where data reduction and discretization come in.
Data Reduction and Discretization
With your data cleaned and transformed into a consistent format, the next question is, how much of it do you actually need? More features don’t always mean better models. In fact, dimensionality can actively hurt performance — a problem so well-documented it has its own name.
The curse of dimensionality describes how model accuracy deteriorates as the number of features grows without a proportional increase in training data. Principal Component Analysis (PCA) addresses this by projecting high-dimensional data onto fewer components that capture the most variance, reducing noise without sacrificing meaningful signal.
For feature selection specifically, three core strategies exist:
Filter methods — rank features independently using statistical scores
Wrapper methods — evaluate subsets by training models iteratively
Embedded methods — perform selection during model training (e.g., Lasso regularization)
Finally, discretization converts continuous attributes — like income or temperature — into labeled intervals. This makes data more interpretable for certain algorithms and can reduce the impact of outliers that slipped through earlier cleaning stages.
Thoughtful data reduction doesn’t strip away information — it removes the noise that obscures the patterns worth finding.
Knowing what to reduce is half the battle. The other half is putting these techniques to work in actual code — which is exactly where we’re headed next.
Theory only takes you so far. At some point, you need to open a code editor and actually preprocess data. Here’s a practical four-step workflow that ties together everything covered in previous sections — cleaning, transforming, and reducing — into a coherent Python pipeline.
Step 1: Load Your Data with Pandas
Start with pandas.read_csv() or read_excel() to pull your dataset into a DataFrame. From there, df.info() and df.describe() give you an immediate snapshot of data types, non-null counts, and statistical summaries. These two lines alone will surface most structural problems before you write a single preprocessing function.
Step 2: Run Exploratory Data Analysis (EDA)
EDA is your diagnostic phase. Use df.isnull().sum() to quantify missing values, df.duplicated() to catch redundant rows, and visualizations like histograms or box plots to spot outliers and skewed distributions. Skipping EDA is the single most common reason preprocessing pipelines fail in production.
SimpleImputer — fills missing values using mean, median, or most-frequent strategies
StandardScaler — standardizes numeric features to zero mean and unit variance
Pipeline — chains these steps to prevent data leakage between stages
Step 4: Validate with Train/Test Splits
Always fit your transformers only on training data using train_test_split, then apply them to the test set. Fitting on the full dataset introduces data leakage, artificially inflating model performance metrics.
Mastering this workflow builds the kind of practical, job-ready expertise that organizations across fast-growing sectors increasingly demand — which naturally raises the question of how to formally validate those skills.
Mastering Preprocessing for a Career in India's Tech Sector
The Python workflow outlined earlier isn’t just academic practice — it maps directly to skills employers are actively hiring for. India’s BFSI sector (banking, financial services, and insurance) and rapidly scaling e-commerce platforms generate enormous volumes of messy, inconsistent data daily. Roles focused on data cleaning, feature engineering, and pipeline automation are consistently among the most in-demand positions across these industries.
In practice, hands-on ability matters — but formal certification is what gets your résumé noticed. Validated credentials signal to hiring managers that your preprocessing knowledge is structured, not just self-taught trial and error.
Strong preprocessing skills are the entry point, not the finishing line, for a data science career. Explore Jaro Education’s data science programs to build and certify these foundational competencies. As you’ll see in the conclusion, that foundation shapes everything else.
Conclusion
Preprocessing isn’t a preliminary chore — it’s the foundation every reliable AI model is built on. Without clean, well-structured data, even the most sophisticated algorithm produces unreliable results. That truth runs through every section of this guide.
The best place to start is small. Grab a beginner-friendly dataset from Kaggle, apply the steps covered here, and observe what changes. Hands-on practice builds instinct faster than any textbook.
Ready to go deeper? Exploring a structured data science program can sharpen these skills into a genuine competitive advantage — and the most common questions practitioners ask along the way are worth addressing directly.
Frequently Asked Questions
Data preprocessing is the process of cleaning and organizing raw data before feeding it into a machine learning model. Think of it as preparing ingredients before cooking — you wash, chop, and measure everything so the recipe works correctly.
Without clean data, even powerful algorithms produce unreliable results. As researchers note, preprocessing directly determines predictive accuracy — it’s not optional.
Data collection and integration
Handling missing values
Removing duplicates and noise
Feature scaling and encoding
Feature selection and dimensionality reduction
In practice, preprocessing consumes 60–80% of a project’s total timeline. Complexity, data volume, and domain-specific requirements all influence the duration significantly.
Shubham Lal
Lead Software Developer
Shubham Lal joined Microsoft in 2017 and brings 8 years of experience across Windows, Office 365, and Teams. He has mentored 5,000+ students, supported 15+ ed-techs, delivered 60+ keynotes including TEDx, and founded AI Linc, transforming learning in colleges and companies.
Get Free Upskilling Guidance
Fill in the details for a free consultation
Related Courses
Explore our programs
Admission Closed
Post Graduate Certificate Programme in Applied Data Science & AI






 Admission Closed
Admission Closed

 Admission Open
Admission Open



