Snowflake Schema in Data Warehouse Model: Explained With Examples
J
By Dr. Sanjay Kulkarni
February 5, 20269 min read
Last updated on March 18, 2026
SHARE THIS ARTICLE
Table Of Content
What Is a Snowflake Schema in Data Warehousing?
Snowflake Schema Diagram Explanation
Key Components of Snowflake Schema
How Snowflake Schema Works
When you're trying to make the best decisions for your business, how do you do it when all your sales, customer, and product data is in separate locations, and the numbers don't match? Reports take forever to generate, numbers don’t align, and analysts spend more time fixing data than analysing it. As data volumes grow, this chaos only gets worse, slowing down insights when you need them most.
This is where Snowflake Schema comes in to keep data organised into clean, normalised, and well-related tables. This also reduces redundancy, increases storage efficiency, and maintains a high level of data integrity. But is the Snowflake Schema structure the appropriate model for all organisations?
In this blog, we will discuss the snowflake schema used in data warehouse systems, how it works with examples, compare it with the star schema, and review the reasons and circumstances that lead businesses to adopt it.
What Is a Snowflake Schema in Data Warehousing?
*datacamp.com
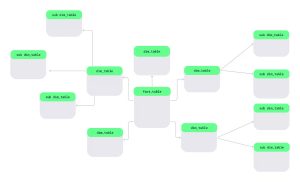
The snowflake model type schema is a variant of the star model schema in a data warehouse. It contains a fact table, like in the star schema model and multiple dimension tables. Dimension tables in a snowflake schema can have multiple related sub-dimension tables that are normalised. And the visual structure looks like a snowflake, which is where it gets its name.
It’s important to understand that the snowflake structure applies only to dimension tables. Fact tables continue to store crucial business data, such as sales amounts, quantities sold, and transaction counts. Snowflake schema in data warehouse is best used when maintaining high data accuracy and consistency, and ensuring efficient storage use are priorities.
Snowflake Schema Diagram Explanation
Let’s see a snowflake schema example to make things easier to understand.
In this type of schema, the Fact table is located at the centre of the model and contains all numerical measurements for your business, including sales. The Fact table connects to dimension tables, which contain descriptive information about the measurements in the Fact table, such as Product and Salesperson. The dim tables are then subdivided into additional tables, creating a visual appearance similar to a flake of snow.
As an example, there is a product dimension table containing a list of products along with a category table to identify the categories under which the products fall. Similarly, there would be a set of customer dimension tables that provide detailed information about the customers in the system, including geographic locations and purchases.
*datacamp.com
Key Components of Snowflake Schema
A snowflake schema consists of several connected components that work together to store, organise, and analyse data effectively. Each element plays a specific role in maintaining structure and performance.
Fact Table
The fact table is located at the centre of the snowflake schema and has the core business metrics being analysed. These metrics are usually numeric values such as revenue, sales quantity, profit, or transaction counts. Along with these measures, the fact table includes foreign keys that reference the associated dimension tables.
Dimension Tables
Dimension tables provide descriptive context to the data stored in the fact table. They answer questions such as who, what, where, and when. Common dimensions include customer details, product information, geographic location, and time periods.
Sub-Dimension Tables
What makes the snowflake schema different from the star schema is its sub-dimension tables. These sub-dimension tables keep detailed attributes so that you do not have to repeat them within a single dimension table. For example, you may have a location dimension that contains cities, states, and countries, with each in its own table and connected via foreign keys.
Relationships and Keys
Primary and foreign keys link all tables in a snowflake schema. The connection between the tables using these keys helps to maintain data integrity. Thus, it enables the user to perform complex analytical queries across multiple dimensions of data.
How Snowflake Schema Works
To understand how a snowflake schema works in practice, let’s consider a simple retail sales scenario.
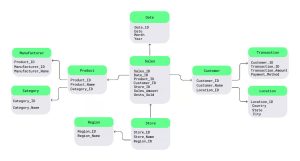
Imagine a company that wants to analyse its sales performance across different products, locations, and time periods. The central fact table called Sales_Fact is used to hold all of the measurable aspects of sales, i.e. total sales dollar amount and quantity sold, and each record in it contains keys (the foreign keys) that relate to individual entries in the dimension tables.
For example, instead of having a single product dimension table that contains all product information, the snowflake schema allows separating it across multiple tables.
The product table may contain the product ID and name, which links to a category table.
The category table may then be further broken down into a department table.
In addition, the location dimension can be broken down into three separate tables to represent city, state, and country levels.
When a user runs a query to consider sales by department and country, the database must perform a series of table joins between the Sales_Fact table and the dimension and sub-dimension tables.
This requires additional joins compared to a star schema, but it also helps maintain the data’s cleanliness, consistency, and non-redundancy. This example demonstrates the effectiveness of a snowflake schema for structured and scalable data analysis.
Advantages of Snowflake Schema
A snowflake schema is a type of database schema designed to improve the overall organisation and efficiency of a data warehouse by using a structured and normalised data model.
Data Integrity
One of the biggest advantages of the snowflake schema is improved data integrity. Since dimension tables are normalised, redundant data is minimised, and each piece of information is stored only once.
Require Less Disk Space
The snowflake schema requires minimal disk space compared to denormalised models like the star schema. This is particularly beneficial for large-scale data warehouses where storage costs can increase rapidly.
Eases Database Organisation
All of the dimension tables in the snowflake schema are organised hierarchically, which allows for a more logical structure of data relationships of all of the data elements.
Easy to Update and Maintain
With the snowflake schema, the dimensions of the dimension hierarchy are stored in separate tables but still share defined relationships, allowing for single-dimension updates to be made without impacting the entire snowflake schema. This is beneficial as the need for data evolves.
Disadvantages of Snowflake Schema
Here are the disadvantages of using a snowflake schema
Performance Issues
If the schema is not well-optimised or data distribution is uneven, query execution may become slower and require more system resources.
Reduced Flexibility
If the schema is not carefully designed, adapting it to changing business requirements can become time-consuming and complex.
Data Redundancy
In certain cases, a snowflake schema may still lead to data redundancy, especially when similar attributes exist across multiple dimension tables. This can create challenges in maintaining data consistency and may increase storage requirements if not managed properly.
Increased Complexity
The snowflake schema is more complex to design, understand, and maintain compared to simpler schemas. The presence of multiple-dimensional tables and numerous foreign key relationships increases the overall complexity of the database.
The discussion around star schema vs snowflake schema is common in data warehousing because both schemas are designed to support analytical reporting but differ significantly in structure, performance, and use cases.
The table below explains these differences in a detailed and descriptive manner to help you clearly understand when to use a star schema and snowflake schema.
Basis of Comparison
Star Schema
Snowflake Schema
Schema Structure
In a star schema, all dimension tables are directly connected to the central fact table.
In a snowflake schema, dimension tables are normalised and split into multiple related sub-dimension tables.
Data Normalization
Star schema uses a denormalised approach where dimension attributes are stored together in one table. While this leads to data duplication, it simplifies data access and reduces the number of joins required during query execution.
It follows a normalised approach by storing dimension attributes in separate tables. This reduces redundancy and ensures that shared attributes are maintained consistently across the data warehouse.
Query Performance
Because all dimensions connect directly to the fact table, star schema queries require fewer joins. This results in faster query execution, making it ideal for dashboards, reporting, and real-time analytics.
Queries in a snowflake schema involve multiple joins across dimension and sub-dimension tables. This can slightly impact performance, especially in traditional systems, though modern data warehouses handle this efficiently.
Storage Efficiency
Due to denormalisation, star schemas consume more storage space as the same dimension data may be repeated multiple times.
Snowflake schemas are more storage-efficient because dimension data is stored only once and referenced using keys.
Scalability and Complexity
Star schemas work best for smaller or moderately sized data warehouses where simplicity and performance are the main priorities.
They handle detailed hierarchies and growing dimensions more effectively, making them ideal for enterprise-level data warehousing.
Best Use Case
Star schema is commonly used for business intelligence, reporting, and dashboarding applications where fast query performance and ease of use are essential.
Snowflake schema is preferred for complex analytical systems where data accuracy, storage efficiency, and structured hierarchies are more important than query simplicity.
When to Use Snowflake Schema
The Snowflake Schema is an ideal database design choice in cases when data is well structured and has clear hierarchical relationships
For companies that have very large and complicated data sets (for example: multiple levels of Products, multiple levels of Geography, multiple levels of Organisation), the snowflake schema will typically be beneficial to those companies.
The snowflake schema is preferred by businesses that need accurate and well-maintained records. It helps keep dimension data consistent across multiple systems and works well with modern data warehouse platforms that can efficiently handle complex joins and normalised table structures.
Real-World Use Cases of Snowflake Schema
The snowflake schema is widely adopted across various industries and business functions where data accuracy, consistency, and structured hierarchies are essential.
Healthcare Sector: The snowflake schema keeps detailed information, treatment histories, medical procedures, and departmental structures. This allows healthcare organisations to analyse patient care patterns while maintaining accurate and well-organised records.
Education Sector: Universities and academic institutions use this schema to track student enrollments, course offerings, faculty information, and grading systems in a structured manner.
Social Media Platforms: It helps to analyse user activity, content interactions, and group memberships. By organising user data into normalised tables, these platforms can efficiently manage large volumes of interconnected information.
Finance and Accounting: The teams use Snowflake schemas for regulatory reporting, risk assessment, and audit tracking, where maintaining consistent and accurate historical data is crucial.
Supply Chain and Logistics Operations: It helps manage product hierarchies, supplier details, warehouse locations, and inventory movement efficiently.
Snowflake Schema in Modern Data Warehouses
Cloud-based data warehousing has significantly improved snowflake schema usability and performance. This has also resolved many of the traditional performance issues associated with multiple joins through the use of advanced query optimisation, computation resource scaling, and columnar data storage formats. The result is that snowflake schemas can now be used more effectively and efficiently than ever before.
As the snowflake schema gains popularity on data warehouse platforms, it is typically used in conjunction with distributed processing, query caching and all of the advanced indexing methods available in the marketplace. By providing these capabilities, organisations can effectively benefit from normalised data models’ advantages (reduced redundancy and increased data integrity) without compromising either query speed or analytical performance, thus positioning the schema to continue to be an excellent choice for cloud-driven analytical environments.
Conclusion
A snowflake schema is a strong data modelling method that helps you create a well-organised, structured data model for your complex analytic environment.
If you want to learn snowflake schema concepts in depth and understand how to apply them in real-world data warehousing scenarios, Jaro Education’s online courses are a trusted choice. Our industry-aligned curriculum and expert-led training can help you gain practical skills in data modelling, analytics, and modern data architectures, preparing you to grow confidently in the fields of business analytics and data science.
Frequently Asked Questions
The primary goal is to reduce data redundancy and improve data integrity by normalising dimension tables.
Neither is universally better. The choice depends on data complexity, performance needs, and storage considerations.
It can require more joins, but modern data warehouses minimise this impact through optimisation.
It is commonly used in enterprise data warehouses, financial systems, healthcare analytics, and CRM platforms.
Dr. Sanjay Kulkarni
Data & AI Transformation Leader
Dr. Sanjay Kulkarni is a Data & AI Transformation Leader with over 25 years of industry experience. He helps organizations adopt data-driven and responsible AI practices through strategic guidance and education. With experience across startups and global enterprises, he bridges the gap between theory and real-world application. His work empowers teams to innovate and thrive in AI-driven environments.



 Admission Open
Admission Open Admission Open
Admission Open Admission Open
Admission Open





