Data Wrangling vs. Data Engineering: What’s the Difference and Why it Matters?

Table Of Content
- The Foundation: Understanding Data Wrangling
- What Exactly Is Data Engineering?
- The Role of Data Wrangling in the Analytics Pipeline
- The Scope and Responsibilities of Data Engineering
In the era of data-driven decision-making, the ability to collect, process, and analyze data efficiently has become a cornerstone of organizational success. From e-commerce giants to healthcare systems, every modern enterprise depends on clean, structured, and actionable data. However, before analytics can deliver insights, data must first be transformed from raw chaos into usable information. This is where two critical processes come into play — data wrangling and data engineering.
Although these terms are often used interchangeably, they serve distinct yet complementary roles within the broader data ecosystem. Understanding the difference between data wrangling vs. data engineering is vital for anyone entering the data profession or managing data-driven projects. Let’s explore these concepts in depth and understand how they fit into the fundamentals of data engineering.
The Foundation: Understanding Data Wrangling
In simpler terms, data wrangling is the hands-on, often meticulous process of taking messy, unstructured datasets and preparing them for business intelligence tools, analytics, and machine learning models. It involves identifying errors, handling missing values, standardizing formats, and integrating multiple sources of information.
In the world of data wrangling vs. data engineering, wrangling focuses more on the micro-level of data preparation, ensuring data quality and consistency at the individual dataset level. It’s the difference between having data that exists and having data that’s usable.
What Exactly Is Data Engineering?
The fundamentals of data engineering lie in creating reliable pipelines that can move data from various sources — such as APIs, databases, and real-time streams — into data warehouses or data lakes where analysts and scientists can work with it.
In essence, data engineering provides the backbone that supports all data operations. Engineers build scalable frameworks that automate repetitive data tasks, integrate systems, and ensure data flows seamlessly across the organization. When we compare data wrangling vs. data engineering, it’s clear that engineering is about architecture and scalability, while wrangling is about refinement and usability.\

*k21 Academy
The Role of Data Wrangling in the Analytics Pipeline
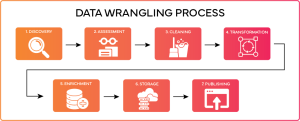
The steps in data wrangling typically include:
- Data Discovery: Identifying and collecting raw data from different sources.
- Data Structuring: Turning unstructured or semi-structured data into tabular formats.
- Data Cleaning: Removing duplicates, correcting mistakes, and filling in missing values.
- Data Enrichment: Combining datasets to provide more context.
- Data Validation: Making sure the processed data meets quality standards.
In the comparison of data wrangling and data engineering, wrangling functions as the “data quality gatekeeper.” No matter how complex a data system may be, insights from low-quality data will always be flawed. Thus, wrangling ensures that analytics rely on reliable inputs, which is essential in data engineering.
The Scope and Responsibilities of Data Engineering
A typical data engineering workflow includes:
- Designing data structure and choosing storage technologies.
- Automating data ingestion pipelines for a continuous data flow.
- Maintaining data quality through monitoring and validation tools.
- Optimizing query performance for analytics and reporting.
When comparing data wrangling and data engineering, engineering emphasizes the automation and scalability of data workflows. While wrangling may involve manual data cleaning in tools like Python or Excel, engineering uses big data technologies such as Apache Spark, Kafka, Snowflake, and Databricks.
This difference highlights a fundamental aspect of data engineering — developing systems that make data accessible, reliable, and ready for analysis at scale.
Data Wrangling vs. Data Engineering: Key Differences
| Aspect | Data Wrangling | Data Engineering |
| Focus | Cleaning and preparing raw data | Building and managing data infrastructure |
| Scale | Works with specific databases | Works with large-scale data systems |
| Goal | Ensures data quality and usability | Ensure data availability and scalability |
| Tools Used | Python, R, Excel, Pandas, Power Query | SQL, Spark, Hadoop, Kafka, Airflow |
| Output | Ready-to-analyze datasets | Automated pipelines and data architectures |
| Who Performs It | Data analysts, data science | Data engineers, architects |
While both roles focus on data quality, data wrangling is usually a smaller part of the larger data engineering process. Essentially, wrangling gets the data ready, while engineering builds the system that manages the data. Both are essential in the basics of data engineering.
*Zuar
How Data Wrangling Complements Data Engineering
In modern organizations, data engineers often build automated wrangling processes into pipelines. For instance, a data engineer may design an ETL system that includes automated cleaning scripts — essentially embedding data wrangling tasks within the broader engineering workflow.
This integration is central to the fundamentals of data engineering, which emphasize not only scalability but also the accuracy and readiness of data for analytical use. The synergy between data wrangling vs. data engineering ensures that business intelligence teams can focus on insight generation rather than data preparation.
Tools and Technologies Powering Data Wrangling and Data Engineering
For Data Wrangling:
- Python & R: Popular programming languages for data manipulation.
- Pandas & NumPy: Libraries used for handling structured data.
- Power BI & Tableau Prep: Visual tools for cleaning and transforming data.
- OpenRefine: Used for exploring and fixing messy datasets.
For Data Engineering:
- Apache Spark & Hadoop: Frameworks for distributed data processing.
- Airflow & Luigi: Tools for workflow orchestration.
- AWS Glue & Azure Data Factory: Cloud-based ETL and data integration services.
- Snowflake & BigQuery: Scalable cloud data warehouses.
When comparing data wrangling vs. data engineering, the choice of tools often depends on the scale and complexity of data tasks. Wrangling tools focus on data manipulation and transformation, while engineering tools handle architecture, automation, and data flow. Together, they represent the technological backbone of the fundamentals of data engineering.
Why Understanding the Difference Matters
When organizations do not distinguish between the two, they risk duplicating efforts or creating bottlenecks in their data pipelines. For example, assigning a data engineer to perform manual wrangling tasks wastes resources. Expecting a data analyst to build scalable data systems can lead to performance issues.
By clearly defining the roles of data wrangling and data engineering, teams can allocate responsibilities effectively. This helps streamline operations and improve data quality. This distinction is also essential for career development. Data engineers focus on automation and system design, while wranglers and analysts develop skills in data transformation and modeling.
Ultimately, understanding both roles strengthens the foundation of data engineering. It allows organizations to build strong, end-to-end data ecosystems.
The Future of Data Wrangling and Data Engineering
As data volumes keep growing, both data wrangling and data engineering are changing quickly. Automation and AI are transforming how data is processed. They reduce manual work while increasing efficiency.
In the future, tools powered by machine learning will handle routine data wrangling tasks such as spotting anomalies and validating data automatically. Meanwhile, data engineering will continue to build scalable cloud-based systems that can support real-time analytics and advanced AI workloads.
This change shows that data wrangling and data engineering are not in competition; they work together. The better each process is, the stronger the foundation for data-driven innovation becomes. Mastering both areas is becoming essential for modern data professionals aiming to grip the fundamentals of data engineering.
Conclusion: Building the Bridge Between Wrangling and Engineering
In today’s data-driven world, every successful analytics project relies on two pillars: efficient data wrangling and solid data engineering. While wrangling focuses on cleaning and preparing data for analysis, engineering builds the systems that enable large-scale data operations.
Understanding data wrangling vs data engineering helps organizations create smoother data pipelines, higher data quality, and quicker insights. Both fields uphold the basics of data engineering, collaborating to turn raw information into strategic value.
As data volume and complexity continue to increase, businesses that invest in both wrangling and engineering excellence will lead the way in analytics maturity. In short, data wrangling prepares data, while data engineering makes data feasible; together, they make insights inevitable.
Frequently Asked Questions

Find a Program made just for YOU
We'll help you find the right fit for your solution. Let's get you connected with the perfect solution.

Is Your Upskilling Effort worth it?

Are Your Skills Meeting Job Demands?

Experience Lifelong Learning and Connect with Like-minded Professionals

