What is K-Means Clustering Algorithm In Machine Learning?

Table Of Content
- Clustering Analysis In Machine Learning
- K-Means Clustering Algorithm Explained
- How K-Means Clustering Algorithms Work?
- Mathematical Intuition Behind K-Means Clustering
Machine learning has brought about a dramatic shift in the way individuals, as well as organizations and developers, prefer to deal with a large amount of information for deriving key results. Among the various processes used in machine learning, the role played by clustering is very important for handling unknown trends. The most common and popular form of clustering used in machine learning is k-means clustering.
In essence, k-means clustering in machine learning is an unsupervised learning algorithm whose primary job is to cluster similar data points based on their similarity. Unlike most supervised algorithms, the process doesn’t utilize labeled datasets. Its primary objective is to divide a given dataset into k non-overlapping clusters and assign each datapoint to the cluster closest to the mean.
It is vital for anyone pursuing or already pursuing a career in the domain of data science or machine learning to understand how the k-means clustering works. Customer segmentation, image compression, and anomaly detection are some of the numerous applications of the k-means clustering. This blog aims to give you an insightful knowledge of the k-means algorithm, how it works, its advantages, disadvantages, and applications.
Clustering Analysis In Machine Learning
Unlike the hierarchical and density-based clustering techniques, k means clustering demands prior knowledge of the number of clusters. This known number is denoted by k and plays an important role in determining the resultant output. In spite of this constraint, k means clustering is widely preferred because of its efficiency.
K-Means Clustering Algorithm Explained
One of the key characteristics of the k-means clustering technique is that it relies on numerical data. The fact that it is based on distance means that the use of numerical data is often required when the data is categorical.
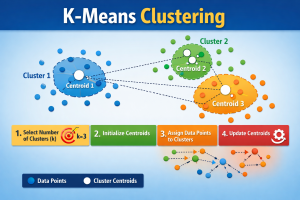
How K-Means Clustering Algorithms Work?
Step 1: Choosing the Number of Clusters (k)
The first step of the k-means algorithm is determining the number of clusters, k. The selection of k is a human choice task that depends on the type of data and the problem that is being attempted to be solved. Determining the appropriate k is important because there is a possibility of underfitting/oversimplification and overfitting due to inappropriate selection.
Step 2: Initialize the centroids
Once a value for k is determined, k centroids are randomly initialized. The centroids are considered initial reference points for forming a cluster. In k-means clustering, it can be considered that a better initial centroids value affects the final clustering result.
Step 3: Assign Data Points to the Nearest centroid
Each observation is assigned to the closest centroid using a distance criterion, usually Euclidean distance. This step creates temporary clusters and is a main step in k-means clustering in machine learning.
Step 4: Recalculate the centroids
With the assignment of all data points done, the next task for the algorithm is to calculate the centroid for each cluster by finding the average of the points in the cluster.
Step 5: Repeat Until Convergence
It is worth pointing out that the assignment and recalculation phases are continued until the centroids have stopped changing noticeably or a fixed number of iterations have been reached. At this point, the k means process has converged.
Mathematical Intuition Behind K-Means Clustering
Choosing the Right Value of k
Elbow Method
The elbow method involves graphing the within-cluster sum of squares for various values of k. The point where the graph bends, resembling an elbow, shows the optimal value. This method is often used in k-means clustering.
Silhouette Score
The silhouette score shows how similar a data point is to its own cluster compared to other clusters. A higher silhouette score means better clustering performance for the k-means algorithm.
Advantages of K-Means Clustering
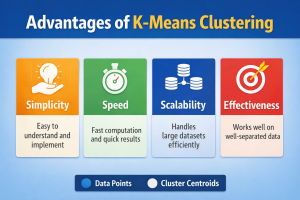
Another benefit is speed. Compared to many other clustering methods, k-means clustering is efficient and quickly reaches a solution when clusters are well separated.
Limitations of K-Means Clustering
Outliers can also greatly impact the k-means algorithm’s performance, as extreme values can distort centroids and affect clusters.
Applications of K-Means Clustering
K-means clustering is used widely across various industries and fields due to its flexibility.
In marketing, it helps with customer segmentation based on buying habits and demographics. In image processing, k-means clustering is useful for image compression by cutting down the number of colors used.
The k-means algorithm is also used for document clustering, recommendation systems, fraud detection, and bioinformatics, highlighting its wide-ranging applications.
K-Means Clustering vs Other Clustering Algorithms
Best Practices for Using K-Means Clustering
Conclusion
The k-means clustering algorithm in machine learning remains one of the most powerful and accessible tools for unsupervised data analysis. Its ability to group data efficiently and uncover hidden patterns makes it invaluable across industries.
While the k-means algorithm has limitations, understanding how it works, along with its strengths and weaknesses, allows users to apply it effectively. With proper data preparation and careful parameter selection, k-means clustering can yield meaningful and actionable insights from complex datasets.
As machine learning continues to grow, k-means clustering will stay a key technique, especially for those starting their journey in data science and artificial intelligence.
Frequently Asked Questions
The important difference will be that KNN is supervised, whereas k means clustering is unsupervised. In k means clustering in machine learning, the k means algorithm will group the unlabeled data, whereas KNN predicts labels using labeled data and nearest neighbors. Their use cases differ based on prediction versus pattern identification.

Find a Program made just for YOU
We'll help you find the right fit for your solution. Let's get you connected with the perfect solution.

Is Your Upskilling Effort worth it?

Are Your Skills Meeting Job Demands?

Experience Lifelong Learning and Connect with Like-minded Professionals

